Explanation, Prediction, and Causality: Three Sides of the Same Coin?
Abstract
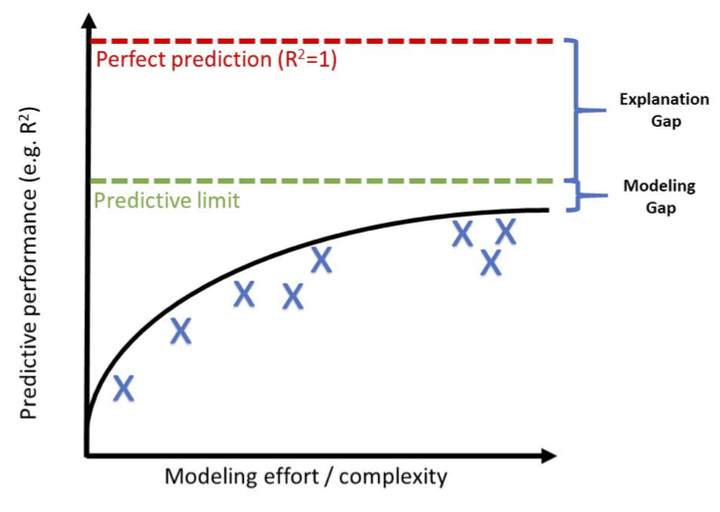
In this essay we make four interrelated points. First, we reiterate previous arguments (Kleinberg et al 2015) that forecasting problems are more common in social science than is often appreciated. From this observation it follows that social scientists should care about predictive accuracy in addition to unbiased or consistent estimation of causal relationships. Second, we argue that social scientists should be interested in prediction even if they have no interest in forecasting per se. Whether they do so explicitly or not, that is, causal claims necessarily make predictions; thus it is both fair and arguably useful to hold them accountable for the accuracy of the predictions they make. Third, we argue that prediction, used in either of the above two senses, is a useful metric for quantifying progress. Important differences between social science explanations and machine learning algorithms notwithstanding, social scientists can still learn from approaches like the Common Task Framework (CTF) which have successfully driven progress in certain fields of AI over the past 30 years (Donoho, 2015). Finally, we anticipate that as the predictive performance of forecasting models and explanations alike receives more attention, it will become clear that it is subject to some upper limit which lies well below deterministic accuracy for many applications of interest (Martin et al 2016). Characterizing the properties of complex social systems that lead to higher or lower predictive limits therefore poses an interesting challenge for computational social science.